
Uncovering the Tricks of OpenAI's GPT
Exploring the Latest Advancements in AI Language Model Identification Techniques



Who am I (least important blog information)?
Hi, I'm Krish Sharma, an EIE undergrad from NIT Silchar. My passion is to play table tennis and listen to music but to sound cool around nerds I am passionate about ML and AI.
Intro to the blog.
Well, well, well. It looks like robots are taking over the writing world and it's only a matter of time before human authors become obsolete. But don't worry, we've got the solution to distinguish human-written content from machine-generated drivel. Enter DetectGPT, the latest AI language model identification technique that promises to uncover the tricks of OpenAI's GPT and expose it for what it truly is: a mediocre attempt at mimicking human writing. So sit back, grab some popcorn, and get ready for a wild ride as we delve into the world of DetectGPT and the latest advancements in AI language model identification.
What is Large Language Model(LLM)?
A large language model is a type of artificial intelligence (AI) system that is designed to generate human-like text. These models are trained on vast amounts of text data, which can range from books, articles, and websites to social media posts, in order to learn patterns and relationships between words, phrases, and sentences. The goal of a large language model is to generate coherent and grammatically correct text that resembles human writing.
Large language models are built using deep learning techniques and can be used for a variety of natural language processing (NLP) tasks, such as text generation, question answering, and machine translation. One of the most well-known examples of a large language model is OpenAI's GPT (Generative Pretrained Transformer), which has been trained on hundreds of billions of words and can generate coherent and informative text on a wide range of topics.
Why Detectgpt is needed?
Protecting against deception: AI-generated text has the potential to be used for malicious purposes, such as spreading false information or impersonating individuals. DetectGPT can help to identify AI-generated text and prevent it from being used for deceptive purposes.
Maintaining trust and credibility: In an era where AI-generated text is becoming increasingly prevalent, it is important to have a way of distinguishing between human-written and AI-generated text. DetectGPT helps to ensure that online communications and media remain trustworthy and credible.
Improving the transparency and accountability of AI systems: DetectGPT helps to increase the transparency and accountability of AI systems by making it easier to detect when AI-generated text is being used and by providing a tool for identifying instances of malicious or biased AI-generated text.
How Detectgpt works?

Detectgpt is a method that distinguishes any human-written text and AI-generated text. To get a rough idea about it, we know some text would be given to the model and the model will predict if that content is human-written or AI-generated. Let's try to understand how that model works.

We aim to determine whether a piece of text was generated by a particular LLM p, such as GPT-3, To classify a candidate passage x, Detectgpt first generates minor perturbations of the passage using a generic pre-trained model such as T5. Then DetectGPT compares the log probability of the original sample against the log probability of the 'perturbed' versions. If the average log probability of the 'perturbed' versions is greater than the original sample, the original sample is likely to be from the source model(Basically LLM).
some very natural questions may arise from reading the above paragraph :
How do we create perturbed text from the original text?
What is log probability and how to calculate it?
No worries, we will get them covered.
How do perturbations of text?

Basically, the perturbation of text is a text-to-text NLP problem. We have many transfer learning models for text-to-text NLP tasks for eg: T5 by Hugging Face.
T5 is a type of artificial intelligence model that has been trained to perform various language tasks such as translation, summarization, and answering questions, among others. It does this by converting each task into a text-to-text format, which means it takes some input text and generates an output text as an answer.
The model is made up of two parts: an encoder and a decoder. The encoder takes the input text and converts it into a numerical representation that the decoder can understand. The decoder then generates the output text based on this representation.
T5 is trained on a large amount of text data using a process called unsupervised learning, which means that the model learns patterns in the data without any specific guidance. Additionally, it is also trained on a smaller amount of text data where the correct output is provided, which is called supervised learning.
To learn more about it you can refer to this
So we can use models like T5 to perturbation of text.
What is Log Probability?
Log probability is a numerical representation of the likelihood of an event or sequence of events. Log probabilities are commonly used in NLP because they allow us to perform probabilistic calculations more efficiently.
In NLP, the log probability of a sequence of words or events is a measure of how likely it is that those words or events occurred in a particular order. For example, in a language model, the log probability of a sentence is a measure of how likely it is that the sentence is grammatical and makes sense.
To understand significance we will try to understand the perplexity of a sentence.
Perplexity in LLM
Perplexity is an evaluation metric for language models.
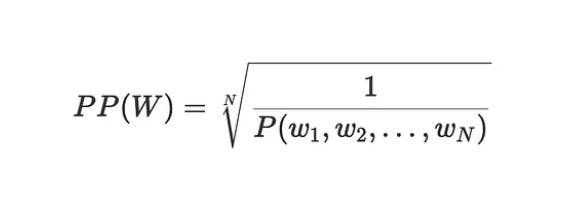
This is the most common definition of perplexity, the normalized inverse of probability. Let's try to make this equation make sense.
We know probability gives the likelihood of words occurring in a certain order. If a word is used frequently the likelihood of it would be higher than some uncommon words. So if we follow this equation perplexity of a common word would be low. For a better understanding, we can think of perplexity as the complexity of a word. If a model is not surprised by a text then it would be considered as low perplexity and high probability.

Now, after understanding all the major concepts :
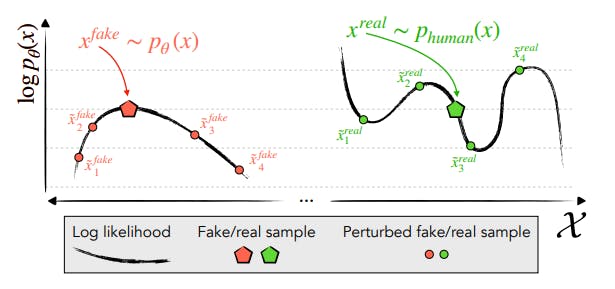
When a machine generates text (x), it often creates text that is not very likely based on the language it was trained on (p(x) is low). This means that if you look at the region around this text in the space of all possible text, other texts generated by the machine are also not very likely (negative curvature of log p(x)). But when a human writes text, it's usually more likely based on the language and therefore doesn't tend to be in these regions of low-probability text.
Limitation
when using probability-based methods to detect machine-generated text, the assumption is made that the log probabilities of the model can be evaluated. However, this assumption is limited because not all models provide the probabilities and even for those that do, it costs money to access this information through APIs like GPT-3. So, evaluating the probabilities is not a straightforward process and can come at a cost.
DetectGPT is more compute-intensive than other methods for detection, as it requires sampling and scoring the set of perturbations for each candidate passage.
Referrals
End
This was my first blog, I hope your time was worth it reading it. Any feedback is welcomed. You can reach out to me on LinkedIn.